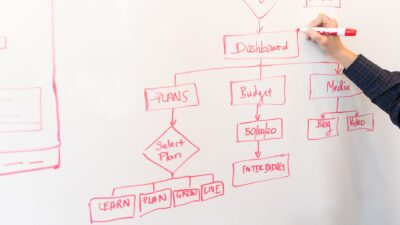
- GroundTruth Writer Kit은 로컬 Ollama가 GitHub 스타·저장소 주소·이미지 같은 사실을 지어내지 않고 기술 글을 자동 생성하도록 만드는 파이프라인 도구 모음이다.
- 모델은 결정론적 코드를 사용해 실제 GitHub API로 데이터를 가져와 사실 시트를 만들고, 이를 바탕으로 글을 작성한다.
- 이미지 URL 검사와 HTML 페이지 교정을 통해 라이브러리의 정확한 정보를 얻어진다.
- 품질 게이트(qc.py)가 단어 수, 코드블록, 사실 일치 여부 등을 검사해 글 작성 과정에서 오류를 줄인다.
들어가며: 로컬 AI 글쓰기의 진짜 벽
로컬 Ollama와 같은 시스템을 사용해 기술 글을 자동으로 생성하는 것은 쉬운 일이지만, 사실 날조가 프로젝트를 죽일 수 있다는 점은 쉽게 깨닫지 못할 수도 있습니다. 모델이 llama.cpp 스타 3,450개라고 착각한 사례에서만 봐도, 실제는 114,288개라는 약 33배의 차이가 있었습니다. 이러한 환각은 단순히 코드가 잘못 작성된 것이 아니라, 모델이 실제로 존재하지 않는 정보를 만들어 낸다는 것을 의미합니다. 이처럼 사실을 정확하게 파악하지 못하면, 기술 글의 신뢰성과 품질이 크게 저하되며, 결국 프로젝트의 성공 가능성이 줄어들게 됩니다.
GroundTruth Writer Kit란 무엇인가
GroundTruth Writer Kit는 로컬에서 작동하는 Ollama와 같은 모델을 사용하여 기술 글을 자동화하는 도구입니다. 이 키트의 핵심은 사실 환각을 방지하는 것입니다. 모델이 잘못된 정보를 생성하지 않도록, 실제 데이터를 수집하고 이를 기반으로 문서를 작성합니다.
키트는 GitHub API를 사용하여 라이브러리의 스타 수, 라이선스, 저장소 주소, 메인테이너 등의 정확한 정보를 가져와서 문서에 포함시킵니다. 이를 통해 생성된 글은 사실을 바탕으로 한 강한 초안을 제공하며, 기술적인 해석과 최종 수정은 사람이 담당합니다.
왜 프롬프트만으로는 환각이 안 고쳐지나
모델이 사실을 모르기 때문에 환각이 고쳐지지 않습니다. 이는 세 가지 근거로 설명할 수 있습니다.
- 모델의 학습 데이터 한계: 모델은 주어진 데이터셋에서 학습한 정보를 기반으로 답변을 생성합니다. 하지만 이 데이터셋은 항상 완벽하지 않으며, 오류나 틀린 정보가 포함될 수 있습니다. 따라서 모델이 잘못된 정보를 배웠다면, 그대로 반복하거나 확장할 가능성이 높습니다.
- 결정론적 처리의 한계: 프롬프트 기반의 방법은 결정론적인 접근을 취합니다. 즉, 모델은 주어진 입력에 대해 고유한 답변을 생성하지만, 이 과정에서 사실 확인이나 검증 단계가 생략될 수 있습니다. 실제 정보와 일치하는지 확인하기 위해서는 직접 데이터를 수집하고 분석해야 합니다.
- 사실과 추론의 차이: 모델은 주어진 정보를 기반으로 추론을 수행할 수 있지만, 이 추론 과정에서 사실과 다른 결과가 나올 수 있습니다. 예를 들어, 모델이 특정 저장소의 스타 개수를 잘못 추론했더라도, 프롬프트만으로 이를 수정하는 것은 불가능합니다. 실제 데이터를 통해 이러한 오류를 확인하고 고쳐야 합니다.
이러한 이유들 때문에 환각을 완전히 방지하기 위해서는 모델에게 직접 사실을 제공하거나, 결정론적 코드를 사용하여 실제 정보를 수집하고 분석해야 합니다.
어떻게 사실 날조를 막나 — 아키텍처
로컬 Ollama와 같은 모델을 사용해 기술 글을 자동화할 때, 진짜 문제는 생성이 아니라 사실 환각이다. 이 파이프라인은 결정론적 코드가 GitHub API를 통해 실제 정보를 가져오고, 모델은 이를 배치하는 원리를 따른다.
- /blob vs raw: 모델이
github.com/.../blob/...pngURL을 사용해 이미지로 취급했지만, 이는 HTML 페이지일 수 있어 깨진 링크가 되어버린다. 따라서 모든 이미지 URL에curlContent-Type 검사를 해서image/*만 통과하도록 하고,/blob/경로는raw.githubusercontent.com으로 교정한다. - content-type 검사: 모델이 잘못된 정보를 제공할 수 있으므로, 각각의 URL을
curl로 요청하여Content-Type헤더가 이미지 타입인지 확인한다. 이를 통해 실제 이미지 URL만 사용하고, HTML 페이지는 무시한다. - 섹션별 생성: 7B 모델은 단발 생성에서 약 650단어 천장이 있어, 고정 골격을 따라 섹션별로 생성한 뒤 이어 붙여 2,000단어와 코드블록 15개 이상을 만든다. 이렇게 하면 각 섹션은 정확하고 일관된 정보를 제공할 수 있다.
- 품질 게이트:
qc.py는 단어 수, 코드블록, 사실 일치 여부, 금지 마케팅 단어, 다국어 동기화 등을 검사한다. 실패 시 발행을 막아, 최종 문서의 품질을 보장한다.
이렇게 하면 모델은 사실을 배치하는 데만 집중하고, 결정론적 코드는 실제 정보를 가져와 정확성을 확보한다.
실전: 키트로 글 한 편 뽑기
- 사실 수집기(fact-fetch)를 실행하여 GitHub API에서 최신 정보를 가져온다.
- 중복 제거기를 사용해 주제를 선택한다(pick-topic).
- 섹션별 작성기(write)를 활용해 각 섹션을 생성하고, 고정 골격에 맞추어 내용을 채운다.
- 번역기를 실행하여 영어·중국어·한국어·베트남어로 번역한다(translate).
- 품질 게이트(qc)를 통과시키기 위해 단어 수, 코드블록, 사실 일치 여부, 금지 마케팅 단어, 다국어 동기를 검사하고 실패 시 수정한다.
- 최종적으로 사람이 기술 해석과 다듬기를 수행하여 완성된 글을 발행한다.
자주 묻는 질문
환각은 어떻게 막나요?
모델에게 직접 사실을 물어보지 않고, 결정론적 코드가 GitHub API를 통해 실제 데이터를 가져와 사용합니다. 이렇게 하면 모델이 창조적인 오류를 범하는 것을 방지할 수 있습니다.
긴 글을 어떻게 생성하나요?
단발 생성에서 약 650단어의 천장 때문에, 고정 골격을 따라 섹션별로 생성한 뒤 이어붙여서 2,000단어와 코드블록 15개 이상을 만듭니다.
품질 게이트는 어떻게 작동하나요?
qc.py 프로그램은 단어 수, 코드블록, 사실 일치 여부, 금지 마케팅 단어, 다국어 동기화 등을 검사합니다. 실패 시 발행을 막습니다.
키트 구성은 어떤 것들이 있나요?
키트는 사실 수집기(fact-fetch), 중복 제거기(pick-topic), 섹션별 작성기(write), 번역기(translate, 4개 언어 지원), 품질 게이트(qc), 엔드투엔드 오케스트레이터(pipeline.sh), 방법론 문서, 실제 생성 예시 글로 구성됩니다.
이 키트의 한계는 무엇인가요?
키트는 사실 안전한 강한 초안을 만들지만, 기술 해석과 최종 다듬기는 사람이 합니다. 따라서 잡일의 약 80%를 없애고 판단이 필요한 20%만 남긴다는 점이 한계로 작용합니다.
정리
사실은 코드가, 글은 모델이, 품질 게이트로 막는다. 사실 시트를 기반으로 작성한 글을 Ollama와 qwen2.5:7b 모델에 입력하여 생성하고, qc.py를 통해 검증된 내용만 포함시켜 최종 문서를 만든다.
관련 가이드
※ 본문의 일부 링크는 제휴(affiliate) 링크로, 가입 시 추가 비용 없이 genyboa 운영에 도움이 됩니다.